Most secret detection programs catch secrets at merge. Here's what happens to everything before the pull request opens.
Most security teams have a secrets detection story that goes something like this: we added secret scanning to our CI/CD pipeline, we're catching credentials before they hit main. The program is running. The box is checked.
That story is true as far as it goes. The problem is how much it leaves out.
API keys, bearer tokens, and service account credentials aren't just leaking through pull requests anymore. They're showing up in CI/CD logs, Slack messages, Jira tickets, S3 buckets, and Confluence pages. The average enterprise has more non-human identities than human ones, and most of those credentials were created by developers moving fast, not by security teams moving carefully. When one of them leaks, the clock starts immediately. Research shows that credentials pushed to public repositories are found and exploited within seconds, often by automated scrapers that run continuously and don't wait for business hours.
PR scanning doesn't see any of that. It sees one gate, at one point in the lifecycle, for one surface. And even at that gate, "caught" and "fixed" turn out to mean very different things.
There's a gap in most secrets programs that nobody talks about because, on the surface, everything looks like it's working.
The lifecycle most teams miss
When a developer writes code, they don't push once and open a PR. They push constantly to back up their work, share progress, and save a Friday afternoon before they log off. Every one of those pushes lands on the remote repository immediately. The secret in commit 3 is live on GitHub the moment that push completes, not when the PR opens, not when the scan runs.
That gap between the first push and whenever a scan finally fires is where the exposure lives. And that's only one of three blind spots that PR-only scanning consistently misses.

The three blind spots
The first is the timing gap. Developers routinely push code to a branch and leave it sitting for hours or days as a draft before formally opening a review. Automated scraping tools that continuously index public GitHub repositories don't wait for PRs. Research shows secrets can be found and exploited within seconds of being pushed.

The second is abandoned branches. A branch that gets pushed but never turned into a PR exists completely outside the reach of CI/CD secret scanning. It sits on the remote repository exposed and even teams that automate stale branch cleanup are closing the door after the secret has already been accessible. Without push or historical scanning, there's no way to know what was on those branches while they were live.
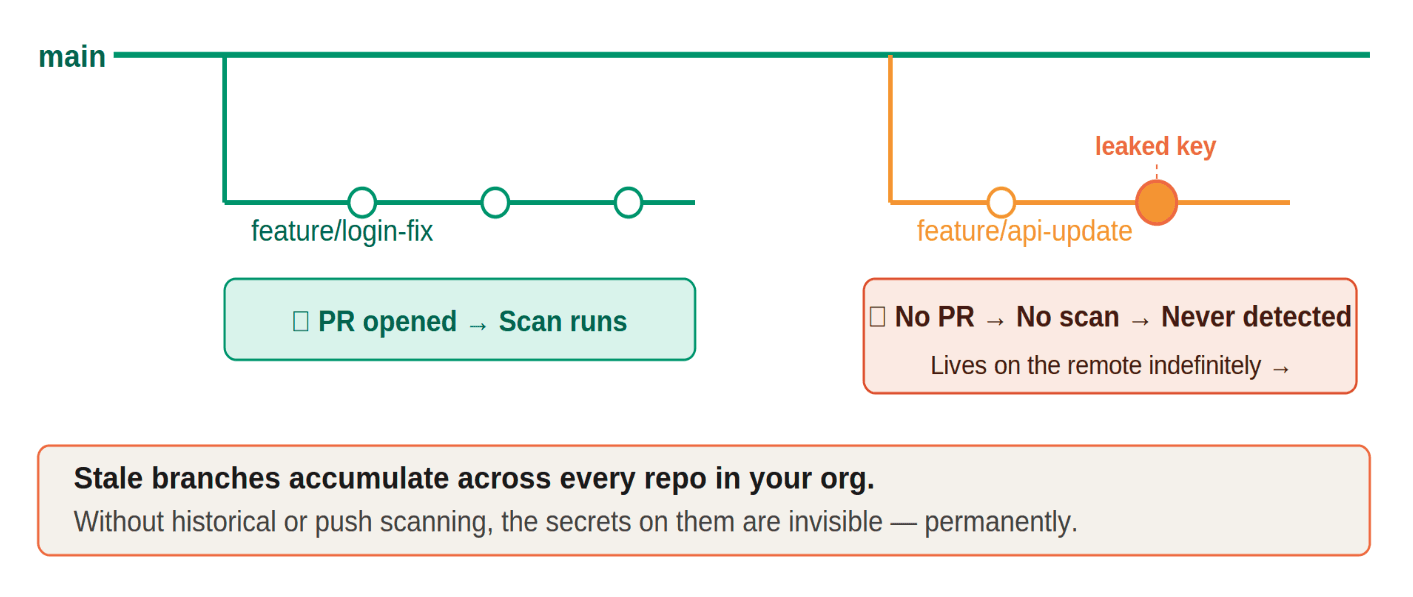
The third is the remediation mismatch, and it's the most frustrating because it happens even when your scanner works. The PR scan fires, catches the secret, and blocks the merge. But then the developer deletes the branch, creates a new one without the secret, and the ticket gets marked fixed. The key was never rotated. It's still active. The commit is still in Git history. The tool did its job and the risk is exactly where it was before.

Closing the gap
Addressing these blind spots requires detection at multiple points across the Git lifecycle, not just at the PR gate. That means real-time push scanning that fires the moment code hits the remote, historical scanning that surfaces everything already sitting on abandoned branches and in commit history, and pre-commit hooks that catch secrets before they ever leave the developer's machine.
It also means rethinking what "fixed" means. A ticket closed is not a secret revoked. The only valid definition of remediation is a key that has been verified dead at the provider, automatically retested and not assumed rotated.
What good looks like
Mature secrets programs don't measure success by how many secrets they find. They measure it by mean time to remediation, confirmed revocation rate, and whether scan coverage actually matches the full surface area where developers work: code, CI/CD, SaaS tools, cloud infrastructure, and history.
The graphic below shows where most teams sit and where the program needs to go. Most teams are at Level 2: PR scanning in place, thinking they're covered. Getting to Level 3 means closing the timing gap and the abandoned branch problem. Level 4 is where detection connects to verified revocation and the program becomes something you can actually report on.
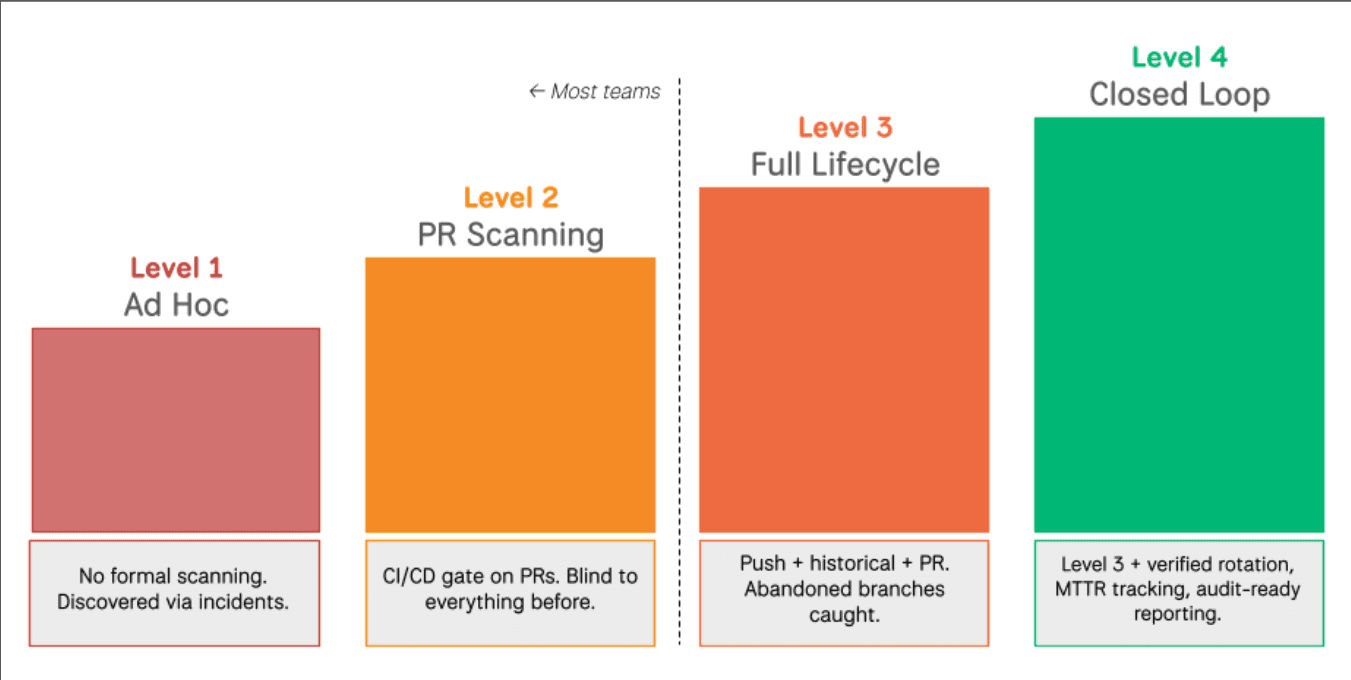
Most teams are at Level 2. The four layer model gets you to Level 3. Closed-loop verification is Level 4.
Join us
On June 25 at 10:00 AM PDT, I will walk through exactly how these blind spots open up, what a four-layer coverage model looks like in practice, and what the difference between "found" and "fixed" actually means for your program..
Register here to learn more!


