TL;DR: I scanned every public GitLab Cloud repository (~5.6 million) with TruffleHog, found over 17,000 verified live secrets, and earned over $9,000 in bounties along the way.
This guest post by Security Engineer Luke Marshall was developed through Truffle Security's Research CFP program. Luke specializes in investigating exposed secrets across open-source ecosystems, a path that led him into bug bounty work and responsible disclosure.
This is the last blog post in a two-part series exploring secrets exposed in popular Git platforms. Check out the Bitbucket research here.
What is GitLab?
GitLab is very similar to Bitbucket and GitHub; it is a Git-based code hosting platform launched in 2011. GitLab was the last of the 3 “big” platforms to be released, but surprisingly holds almost twice as many public repositories as Bitbucket.
It has all the same traits as GitHub and Bitbucket that make it an attractive target for exposed credentials:
It uses Git, which buries secrets deep in commit history.
It hosts several million public repositories.
Discovering all public GitLab Cloud repositories
Much like the Bitbucket research, this research aimed to provide an accurate insight into the state of exposed credentials across ALL public GitLab Cloud repositories. This meant I needed a way to list every single public GitLab Cloud repository.
GitLab exposes a public API endpoint (https://gitlab.com/api/v4/projects) that can be used to retrieve the list of repositories by sequentially paginating through results.
This script below handled this for me.
At the time of the initial research (10/09/2025), GitLab returned over 5,600,000 repositories. Since this scan, around 100,000 new repos have been published.
Building the automation
I used the exact same automation as the Bitbucket research: an AWS Lambda function tied to an AWS Simple Queue Service (SQS) queue. This set me back about $770 USD, but it let me scan 5,600,000 repositories in about 24 hours.
My automation consisted of two main components:
A local Python script that sent all 5,600,000 repository names to an AWS SQS queue, which acted as a durable task list.
An AWS Lambda function to (a) scan the repositories with TruffleHog, and (b) log the results.
The beauty of this architecture meant that no repository was accidentally scanned twice, and if something broke, scanning would seamlessly resume.
The scanning architecture looked like this:
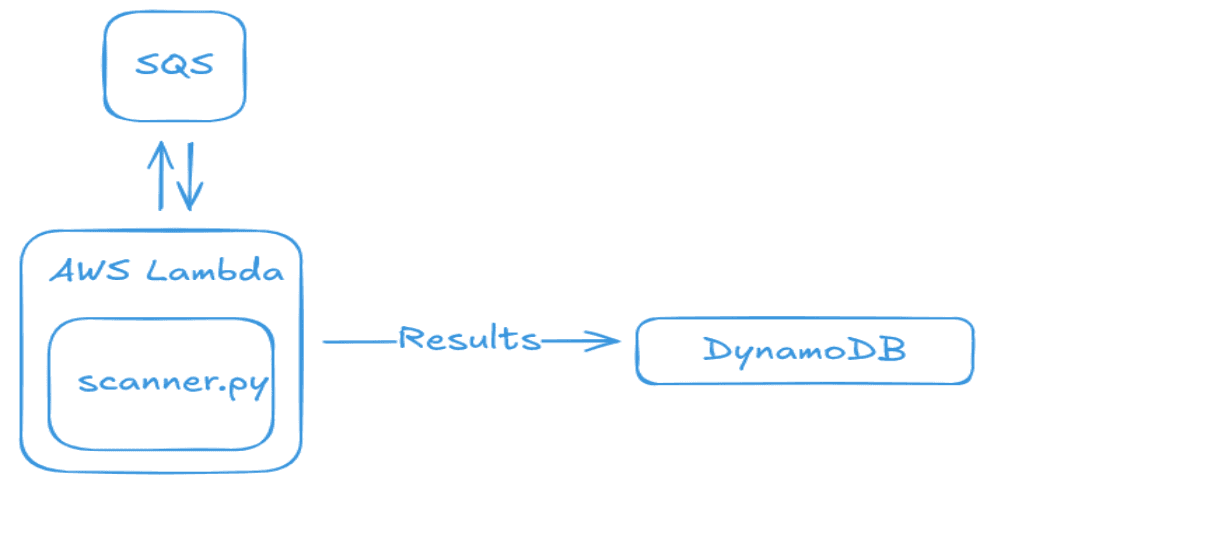
AWS Lambda requires container images to embed the Lambda Runtime Interface Client (RIC) and a handler. Since the pre-built TruffleHog image is Alpine-based, it won't run as a Lambda on its own.
I built a custom Lambda function using an AWS Python base image (which already has the RIC and correct entrypoint), copied the TruffleHog binary into that image, and then invoked it from the handler.
My Dockerfile looked like this:
This is the TruffleHog command that I used:
Each Lambda invocation executed a simple TruffleHog scan command with concurrency set to 1000. This setup allowed me to complete the scan of 5,600,000 repositories in just over 24 hours.
The Results: Comparing GitLab with Bitbucket
When comparing the two platforms, the difference in scale and findings is distinct:
Metric | Bitbucket | GitLab |
|---|---|---|
Public Repos Scanned | ~2.6 Million | ~5.6 Million (2.1x) |
Verified Secrets Found | 6,212 | 17,430 (2.8x) |
While I scanned roughly twice as many repositories on GitLab, I found nearly three times as many verified secrets. This indicates a ~35% higher density of leaked secrets per repository on GitLab compared to Bitbucket.
Secrets Exposed by Date
The graphs below plot the frequency of live secrets exposed on GitLab Cloud and Bitbucket public repositories.
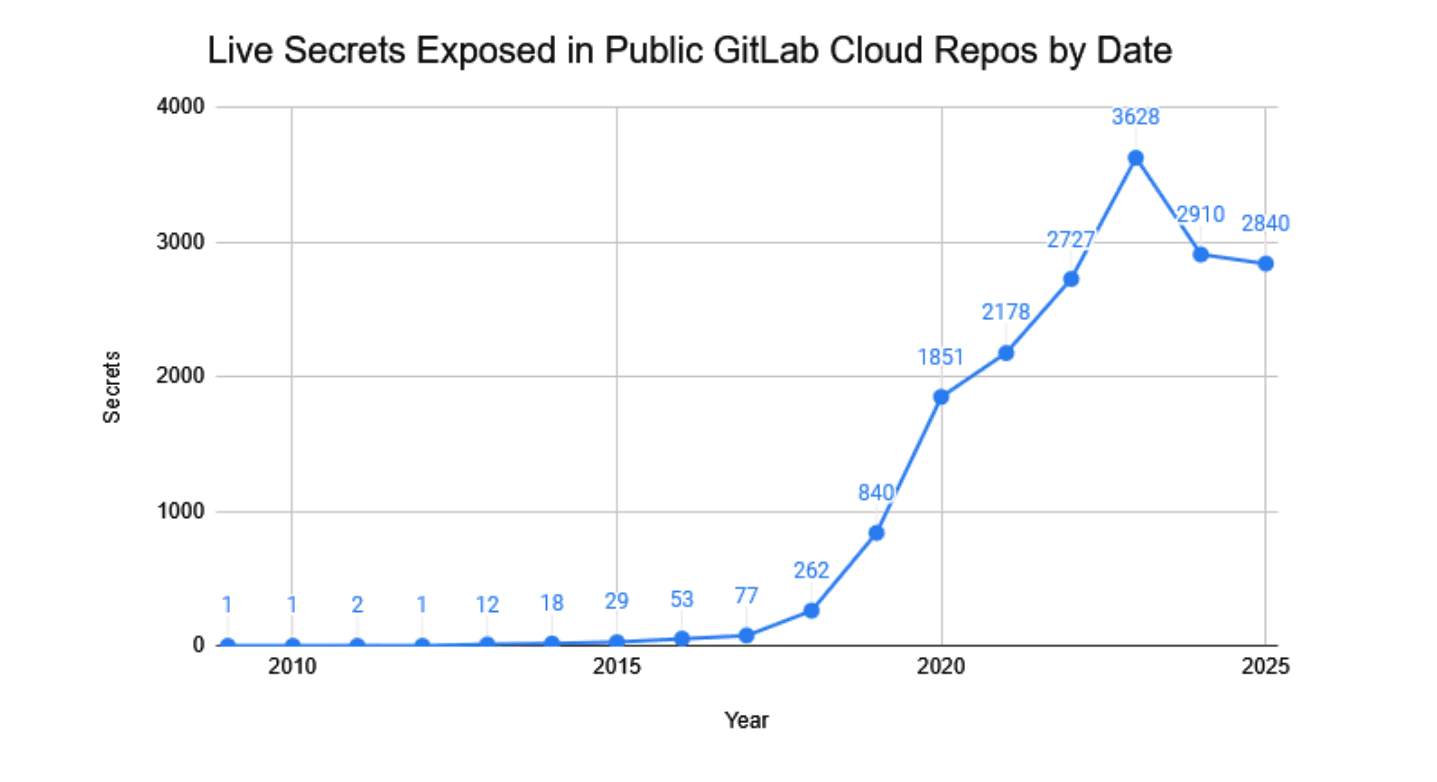
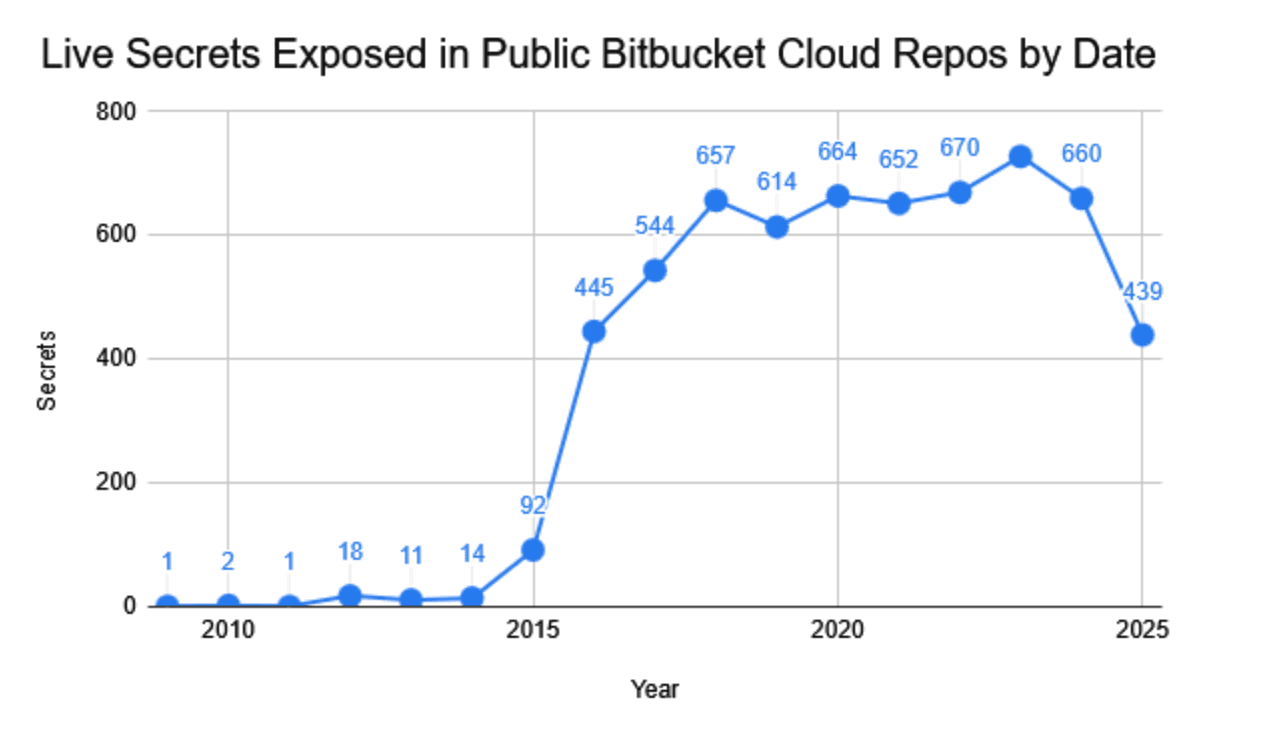
While Bitbucket’s exposure volume has effectively plateaued since 2018, hovering consistently in the mid-hundreds, GitLab experienced an explosive surge during the same period. This divergence suggests that the recent boom in AI development, and the associated sprawl of API keys, has disproportionately impacted GitLab’s more active public repository landscape.
Fun Fact: While Bitbucket has some old secrets, GitLab has some really ancient ones lingering. The earliest commit timestamp for a valid secret is 2009-12-16! These creds must have been imported into this GitLab repository, as they predate GitLab’s release date by almost 2 years!
Secrets Exposed by Type
Like Bitbucket, Google Cloud Platform (GCP) credentials were the most leaked secret type on GitLab repositories. About 1 in 1,060 repos contained a set of valid GCP credentials!
In the graph below, I plotted the most frequently leaked keys by SaaS/Cloud providers.
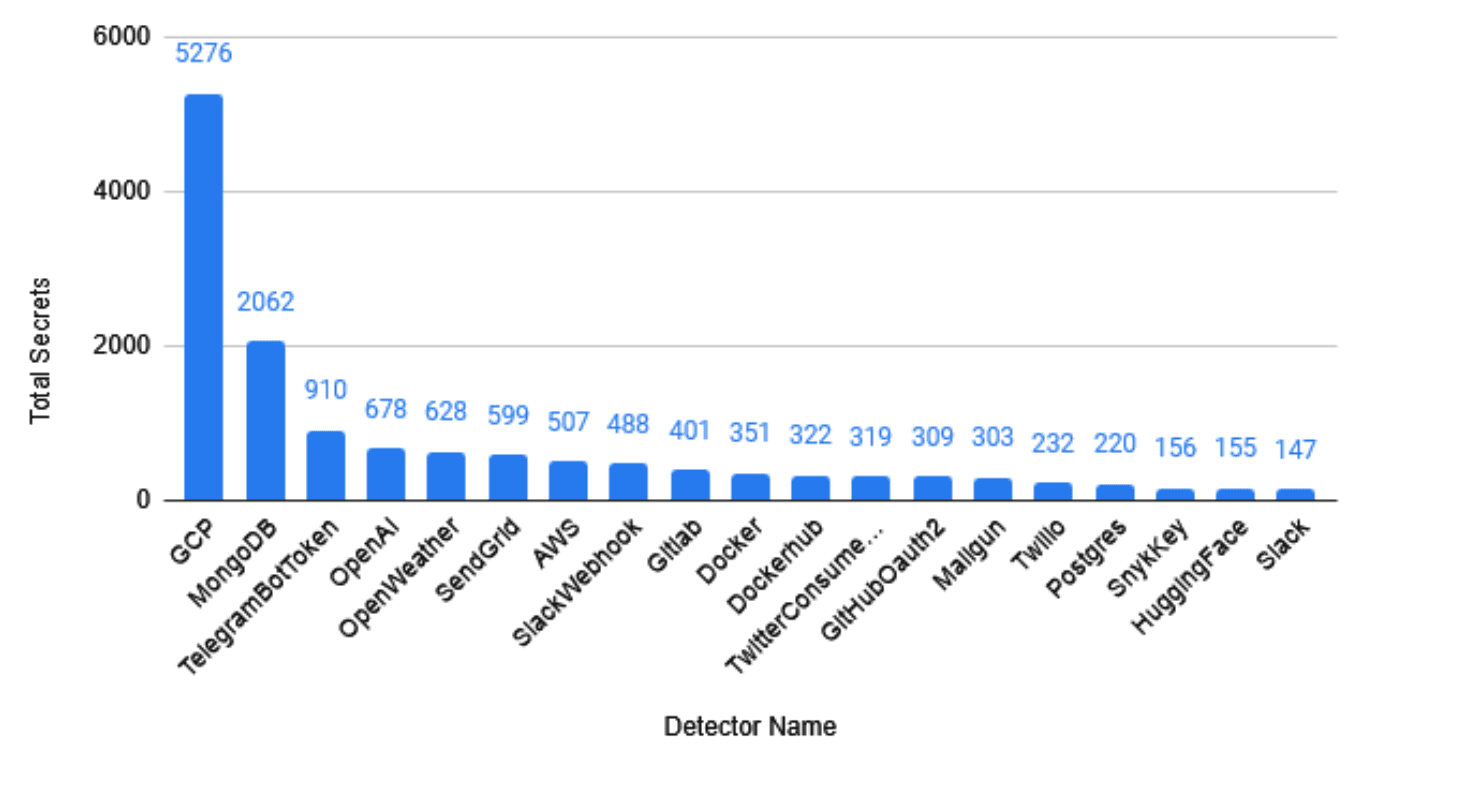
A standout finding was the distribution of GitLab-specific credentials. We found 406 valid GitLab keys leaking in GitLab repositories, but only 16 GitLab keys leaking in Bitbucket. This sharp contrast, 406 vs 16, strongly supports the concept of 'platform-locality': developers are significantly more likely to commit a platform's credentials to that same platform accidentally.
Automating the Triage Process
The 17,430 leaked secrets belonged to 2804 unique domains, which meant I needed an efficient and accurate way to triage the results. I used an LLM capable of performing web searches (Claude Sonnet 3.7) to identify the best path to report a security vulnerability to each organization.
I split the domains into batches of 40 and then sent them to Claude along with this prompt.
Of course, this wasn’t foolproof, and some organizations don’t have defined security programs, so I also “vibed” up a simple Python script that would extract metadata from the TruffleHog results and dynamically generate disclosure emails. I used the role-based email addresses security@, support@, and contact@ as a best effort to reach these organizations, when I couldn’t find a specific email address for a security or executive contact.
Both of these systems worked well and allowed me to disclose the leaked secrets to over 120+ organizations. Separately, I directly reached out to 30+ SaaS providers to work with them directly on remediating their clients’ exposed credentials.
Looking Deeper
One of the core challenges in secret detection on Git platforms is that users committing with personal email addresses might push an organizational secret, or vice versa. Because of this, I tried to focus on relating the secret to an organization rather than just relating the committer to an organization. A good example of this was a Slack Token that was committed by a @hotmail.com address to a public GitLab repo.
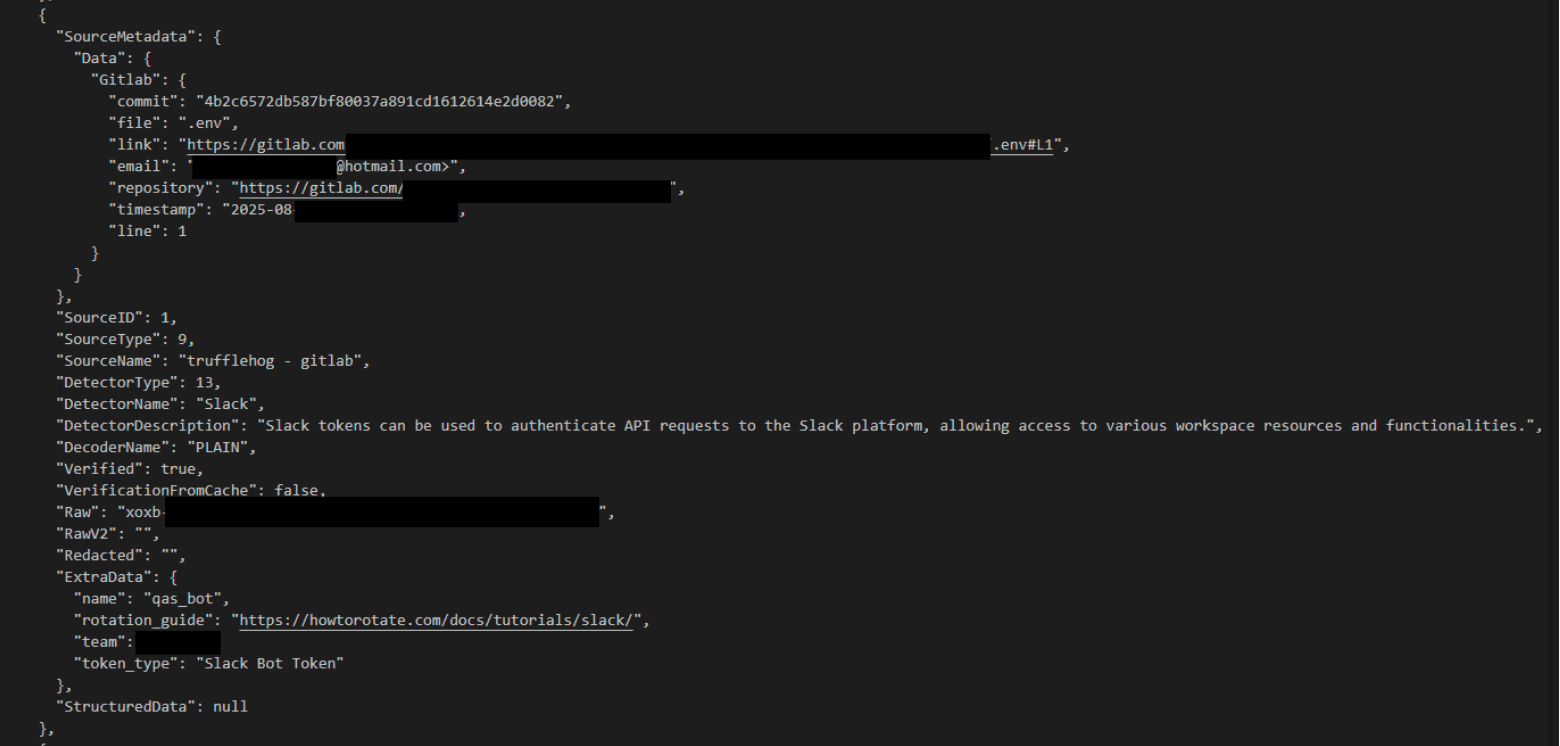
For some secrets, TruffleHog outputs an Extra Data field to aid in triaging. In the case of Slack tokens, TruffleHog outputs the team value, which is often used to identify the organization using the Slack token.
To confirm my suspicions that this might be an organization’s token, I used TruffleHog’s analyze feature to take a look at the secret in more detail:
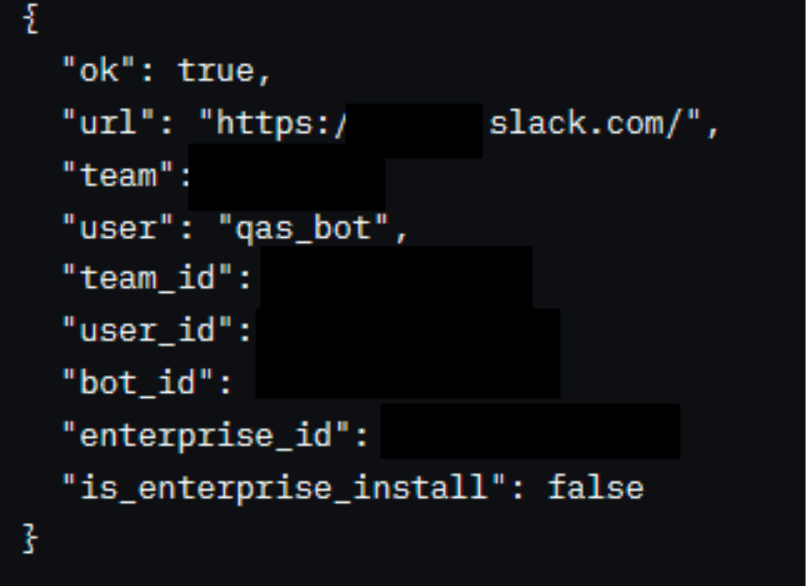
Success! In the url field, I found a link to a Slack instance. After navigating to this page, I saw a login screen for the org’s Okta instance, confirming this token was related to an organization. This secret was accepted as a P1 and paid $2100.
Note: Only run trufflehog analyze on secrets that you own, or when the relevant bug bounty/disclosure program specifically authorizes that type of scanning.
Summary
This project, paired with the earlier Bitbucket study, offers a clear view of how secrets are distributed across major Git platforms. A few key takeaways emerged:
Higher Density, Similar Payouts: While GitLab exposed far more valid credentials (3x the volume of Bitbucket), the total bounty payout was roughly the same ($9,000 vs. $10,000), suggesting that higher volume doesn't always equate to higher critical impact.
The "Zombie Secret" Problem: Both platforms harbor valid credentials dating back over a decade (2009), proving that secrets do not simply expire on their own, they must be rotated.
Platform Locality is real: Secrets tend to leak where they live. We found nearly 25x more valid GitLab tokens on GitLab itself than we did on Bitbucket.
The Cost of Disclosure: Responsibly disclosing secrets across 2,800+ organizations required significant automation and "triage," but it successfully led to the revocation of thousands of live keys.
The bottom line is clear: even mature, enterprise platforms still harbor high-impact exposures. For defenders, this reinforces that disciplined, large-scale scanning is not just a research exercise; it is a necessity.


